
What is it?
One-Class SVM is used for unsupervised outlier and novelty detection. Normal data points to build the model so the algorithm can set a correct boundary for the given samples. Nu, Gamma, and Kernel are parameters for the model these impact the result significantly. So we need to experiment with these parameters until we find the optimal settings for our scenario.
How it works?
Generally SVM separates all the data points from the origin and maximizes the distance from this hyperplane to the origin. This results in a binary function which captures regions in the input space where the probability density of the data lives. Thus the function returns +1 in a “small” region elsewhere it returns −1 .
Boundary detection
The algorithm obtains a spherical boundary, in feature space, around the data. The volume of this hypersphere is minimized, to minimize the effect of incorporating outliers in the solution.
Implementation and results
our goal is to detect change points in a monthly sales amount and quantity of various stores, also known as novelty detection. One-class SVMs have already been applied to novelty detection for time series data. when there is a change points in the these time series are explicitly discovered, representing changes in the sales performed by the store. 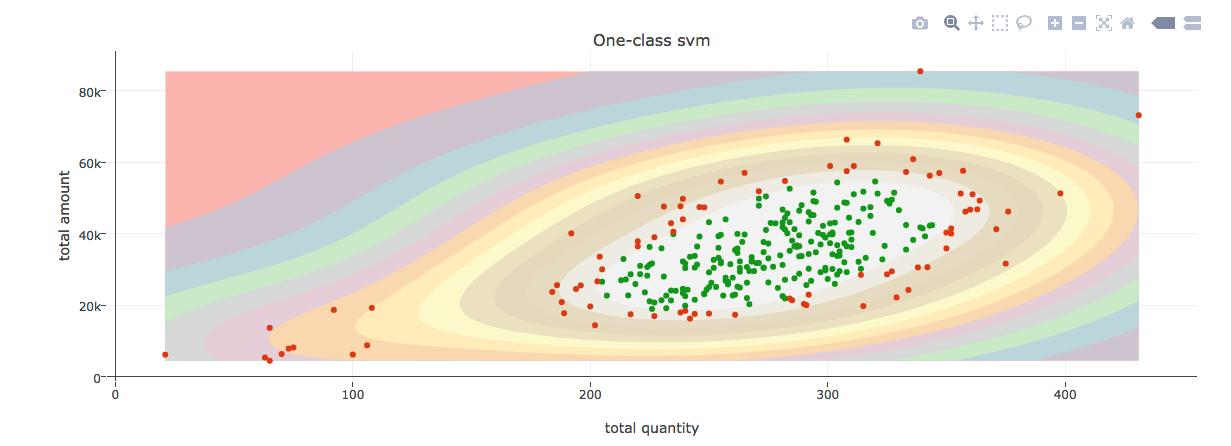 Below is the compare chart of One class SVM, Robust covariance and isolation forest. We can clearly see the difference of outlier detection between these algorithms.
Below is the compare chart of One class SVM, Robust covariance and isolation forest. We can clearly see the difference of outlier detection between these algorithms. 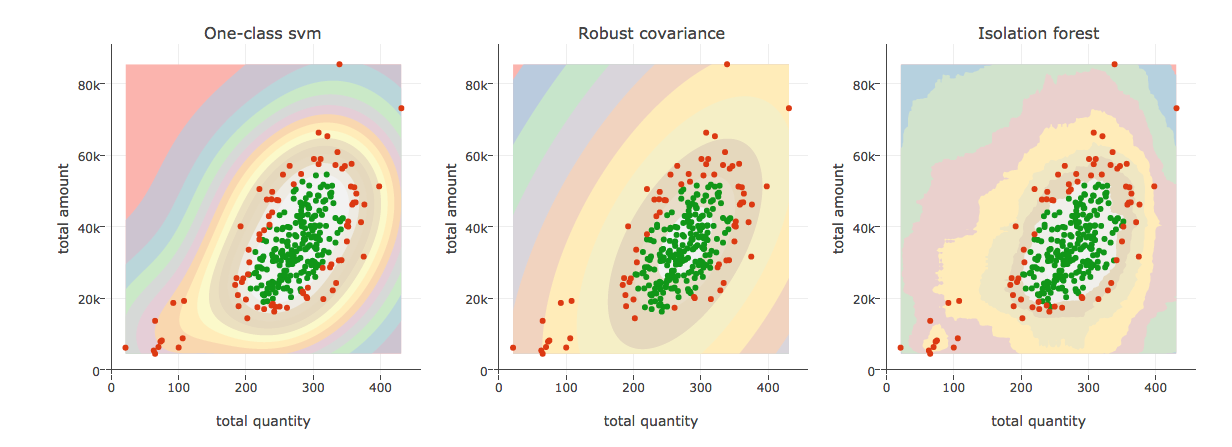

You can do more complex analysis using Bizstats cloud by asking your questions. If you are not tried Bizstats yet, you can try our demo now !
